SIFT(Scale Invariant Feature Transform)는 이미지에서 Feature를 추출하는 대표적인 알고리즘 중의 하나입니다. 이미지의 scale(크기), Rotation(회전)에 불변하는 feature(특징)을 추출하기 때문에, 이미지가 회전해도 크기가 변해도 항상 그 위치에서 뽑히는 특징을 찾아냅니다. SIFT의 방대한 연산량 때문에 이를 해결하기 위해 SURF(Speed Up Robust Feature), FAST(Features from Accelerated Segment Test), 그리고 AGAST 등이 개발되었지만, 성능면에서는 SIFT를 확연하게 상회하는 알고리즘의 개발은 좀 더 시간이 필요한 것 같습니다 [2]. 이미지의 feature(=keypoint)를 찾기 위해, SIFT의 4단계의 절차를 요약하면 아래와 같습니다.
(1) Scale-space extrema detection (이미지의 크기를 변화시켜 극대점, 극소점 detection -> keypoint candidates 찾음)
(2) Keypoint localization (feature matching 시 불안정할 keypoint 제거 및 keypoint를 정확하게 위치시킴)
(3) Orientation assignment (각 keypoint들의 direction, magnitude등의 orientation 결정)
(4) Keypoint descriptor (keypoint를 표현하기 위한 descriptor 생성)
(1)로 인해 scale-invariance(이미지 크기변화에 무관하게 같은 keypoint 추출)한 성질을 가지게 되고, (3)로부터 계산한 keypoint의 orientation을 (4)에서 구한 keypoint descriptor에서 빼주면 rotation-invariance(이미지 회전에 무관하게 같은 keypoint 추출) 성질을 갖게됩니다[3].
(1) Scale-space extrema detection
< Scale-space 만들기 >
Scale-space는 original 이미지의 크기를 변화시켜 여러 scale의 이미지를 모아놓은 집합체입니다. 이미지는 크기별로 Octave 1, 2, 3, 4로 표시합니다. Keypoint를 추출하기 위한 사전작업으로 아래의 그림처럼 Octave별로 5개의 이미지를 만든 다음, 가우시안 필터를 이용하여 점점 더 강하게 bluring 시킵니다. 원본 이미지를 2배로 키워 octave1을 만드는 이유는, 추후에 DoG(Difference of Gaussian) 이미지를 만들 때 활용하기 위해서입니다.

< Dog (Difference of Gaussian) 연산 >
위의 그림에서 같은 Gaussian filter를 이용해 점점 더 bluring 시킨 이미지들을, octave 내에서 인접한 두 개의 이미지를 빼서 아래의 그림처럼 edge 및 detail 정보를 포함한 4개의 이미지를 octave 마다 4개씩 만듭니다. 이것을 DoG(Difference of Gaussian)이라고 합니다. DoG 연산은 image enhancement 알고리즘으로 이미지의 edge나 detail 한 부분의 visibility를 증가시키기 위해 사용됩니다. SIFT 알고리즘에서는 16개의 DoG 이미지를 얻을 수 있습니다.
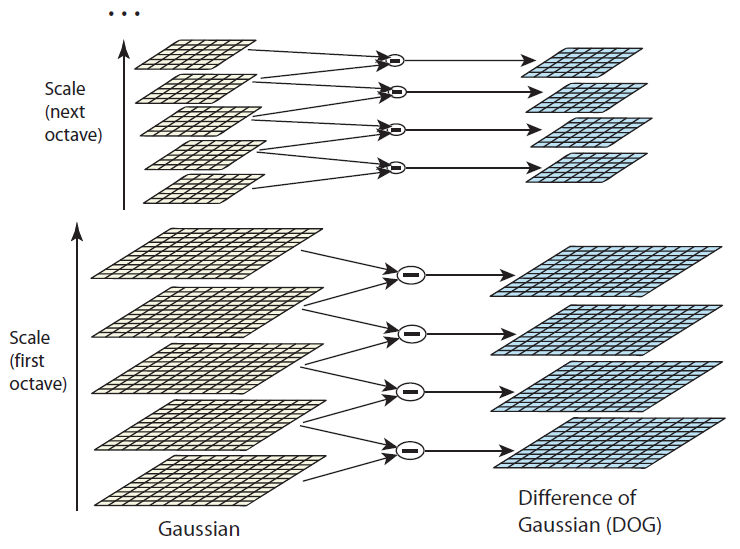
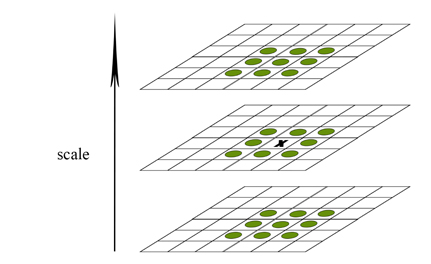
이제 극값(극대 값 또는 극소값)을 얻기 위해 각각의 octave에서 scale이 다른 3개의 이미지를 아래의 그림처럼 겹쳐놓습니다(예를 들어, 1-2-3 또는 2-3-4 --> 1, 4 DoG 이미지에서는 keypoint를 찾을 수 없음). 1개의 x는 검사하는 point, 녹색 circle은 26개의 neibor pixel들입니다. x의 값이 26개의 neibor pixel들과 비교해서 가장 크거나 가장 작으면 keypoint로 간주하고, 그렇지 않으면 keypoint로 정하지 않습니다. 이러한 연산은 각 octave 마다 2번씩 발생하고, octave의 수는 4개이기 때문에 결국 8장의 극값 이미지를 얻게 됩니다 [4].
(2) Keypoint localization
위에서 구한 극값들의 위치는 대략적인 것입니다. 실제 극값의 위치는 pixel들의 사이 공간에 있을 확률이 높습니다. 하지만 우리는 진짜 극값의 위치에 접근할 수 없기 때문에 수학적으로 계산합니다. 아래의 수식은 DoG 이미지에 대한 테일러급수를 나타냅니다. D는 DoG 이미지를 나타내고, X는 (x, y, standard deviation)을 나타냅니다. 아래의 식을 X에 대해 미분해서 0이 되는 지점이 극값이 될 것입니다 [5]. 이러한 방법은 알고리즘이 좀 더 안정적인 성능을 낼 수 있게 도와준다고 합니다.

< 나쁜 keypoint 제거 >
나쁜 keypoint들을 제거하기 위해 수학적으로 계산된 keypoint들 중에서 특정 threshold 보다 낮은 keypoint들을 제거합니다. DoG는 edge를 좀 더 민감하게 찾아내기 때문에 noise가 edge 위에 위치할 경우 keypoint로 오인할 위험이 있습니다. 그래서 edge 위에 위치한 keypoint들 또한 제거하여 코너에 위치한 keypoint들만 남겨놓습니다 [4].
(3) Orientation assignment
Keypoint 마다 방향을 할당해주는 역할을 해주는 단계입니다. Keypoint 주변으로 아래의 두 식을 이용해서 keypoint 주변 gradient의 크기 및 방향을 알아낼 수 있습니다.
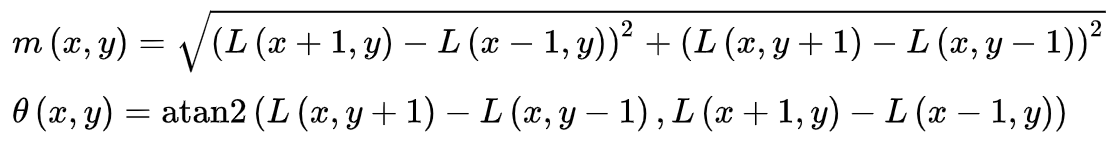

Gradient의 크기와 방향을 구하고 아래와 같이 가로축이 방향, 세로축이 크기인 Histogram을 그립니다. 아래의 Histogram에서 가장 큰 값을 가지는 방향(각도)을 keypoint의 방향으로 설정합니다. 만약 가장 큰 keypoint 방향의 80% 보다 큰 각도가 존재한다면, 그 각도도 keypoint의 orientation으로 설정합니다. 즉, 하나의 keypoint는 여러 개의 orientation을 가질 수 있습니다. 아래의 Histogram은 2개의 orientation을 갖습니다.

(4) Keypoint descriptor
지금까지 keypoint들을 결정하기 위해 여러 가지 절차를 진행했습니다. 이제 이 keypoint들을 식별하기 위한 fingerprint(지문)과 같은 특별한 정보를 부여해주어야 합니다. 아래의 그림처럼 keypoint를 중심으로 16x16 크기의 윈도우를 세팅하고, 이 윈도우를 4x4의 크기를 가진 16개의 작은 윈도우로 구성합니다.

16개의 작은 윈도우에 속한 pixel들의 gradient의 크기와 방향을 계산합니다. 그리고 8개의 bin을 가진 Histogram을 그립니다. 이전과 마찬가지의 방법을 사용하였지만 bin의 수만 8개로 세팅을 하였습니다. 결국 16개의 윈도우에 8개의 방향으로 세팅이 되었기 때문에 16x8=128 개의 숫자(feature vector)를 가진 descriptor를 만들 수 있습니다.
이미지가 회전하면 모든 gradient의 방향이 바뀌기 때문에 feature vector도 변하게 됩니다. 즉, 회전한 이미지에서 같은 keypoint에 대한 feature vector를 보더라도 회전된 만큼 feature vector가 변했기 때문에, 회전된 이미지에서는 feature vector만 보고서 같은 keypoint 인지 알 수 없습니다. 따라서 회전된 이미지에서도 feature vector가 변하지 않도록 하기 위해 16개 각각의 4x4윈도우에서 keypoint의 방향을 빼줍니다. 그러면 각 16개의 윈도우의 방향은 keypoint의 상대적인 방향이 되므로 원래의 이미지에서의 keypoint와 회전된 이미지에서의 keypoint는 같게 됩니다.
이전 frame과 현재 frame의 밝기가 달라지면 feature vector의 값이 달라질 수 있기 때문에 이러한 문제를 해결하기 위해, 전체적으로 어두어지거나 밝아져도 상대적인 밝기는 동일하게 유지되도록 normalization을 줍니다.
이렇게 각각의 keypoint 들에게 fingerprint를 할당해줍니다.
Code
SIFT 알고리즘의 내용은 방대하지만 opencv를 이용하면 쉽게 구현할 수 있습니다. 아래의 코드는 python을 이용하여 구현한 코드입니다. 이미지를 import 할때 경로에 주의해주세요.
import sys
ros_path = '/opt/ros/kinetic/lib/python2.7/dist-packages'
if ros_path in sys.path:
sys.path.remove(ros_path)
import cv2
sys.path.append('/opt/ros/kinetic/lib/python2.7/dist-packages')
def main():
# import image
img = cv2.imread('./data/img_gist_00035.png')
sift_result = None
# Initiate SIFT detector
sift = cv2.xfeatures2d.SIFT_create()
# find the keypoints and descriptors with SIFT
# kp = keypoints
# des = descriptors
kp, des = sift.detectAndCompute(img,None)
# overlay the keypoints on the img
sift_result = cv2.drawKeypoints(img, kp, sift_result, (255, 0, 0))
cv2.imshow('sift_result', sift_result)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Reference
[1] Lowe, D. G. (2004). Distinctive Image Features from Scale-Invariant Keypoints. International Journal of Computer Vision, 60(2), 91–110.
[2] Lee, Jae-Eun, et al. "SIFT Image Feature Extraction based on Deep Learning." Journal of Broadcast Engineering 24.2 (2019): 234-242.
[3] https://ballentain.tistory.com/47
[5] https://en.wikipedia.org/wiki/Scale-invariant_feature_transform
[6] https://m.blog.naver.com/samsjang/220643446825
[7] https://darkpgmr.tistory.com/131
[8] https://docs.opencv.org/master/dc/dc3/tutorial_py_matcher.html
[9] https://datascienceschool.net/view-notebook/7eb4b2a440824bb0a8c2c7ce3da7a4e2/

'Robotics > Vision' 카테고리의 다른 글
| [비전 #3] 카메라 좌표계 (Coordinate) (0) | 2020.09.11 |
|---|---|
| [비전 #2] 카메라 모델 (Camera model: Intrinsic parameter) (0) | 2020.09.04 |
| [비전 #1] 핀홀 카메라 (Pinhole Camera): Focal length(초점거리) (0) | 2020.08.16 |


