Update
2019.8.17: Writing
2019.8.26: Posting
본 포스팅은 github에 업로드한 mnist_dnn repository에 대한 설명이다. 코드에서 사용한 여러가지 API 및 모듈에 대한 해설은 "mnist my own data" 포스트를 참조하기 바란다.
dnn_mnist.py
import tensorflow as tf
import numpy as np
from glob import glob
from PIL import Image
from util import get_label_from_path
from util import data_slice_and_batch
# 1.Hyper Parameter
num_epoch = 2
batch_size = 500
height = 28
width = 28
channels = 1
num_classes = 10
shuffle_buffer_size = 100000
shuffle_buffer_size_test = 20000
# 2-1. Import training dataset
DATA_PATH_LIST = glob('./mnist_png/training/*/*.png')
LABEL_LIST = get_label_from_path(DATA_PATH_LIST)
dataset = data_slice_and_batch(DATA_PATH_LIST, LABEL_LIST, shuffle_buffer_size, batch_size)
# 2-2. Import test dataset
TEST_DATA_PATH_LIST = glob('./mnist_png/testing/*/*.png')
TEST_LABEL_LIST = get_label_from_path(TEST_DATA_PATH_LIST)
dataset_test = data_slice_and_batch(TEST_DATA_PATH_LIST, TEST_LABEL_LIST, shuffle_buffer_size_test, batch_size)
# 3.Model Design
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
W1 = tf.Variable(tf.random_normal([784, 256], stddev=0.01))
L1 = tf.nn.relu(tf.matmul(X, W1))
L1 = tf.nn.dropout(L1, keep_prob)
W2 = tf.Variable(tf.random_normal([256, 256], stddev=0.01))
L2 = tf.nn.relu(tf.matmul(L1, W2))
L2 = tf.nn.dropout(L2, keep_prob)
W3 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L2, W3)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
total_batch = int(len(DATA_PATH_LIST)/batch_size)
for epoch in range(num_epoch):
total_cost = 0
iterator = dataset.make_initializable_iterator()
sess.run(iterator.initializer) # Shuffle이 실행됨
for i in range(total_batch):
# batch_xs, batch_ys = mnist.train.next_batch(batch_size)
image, label = sess.run(iterator.get_next())
batch_xs = image.reshape(batch_size,784)
batch_ys = tf.one_hot(label, depth=num_classes).eval(session=sess)
# print(batch_ys)
a, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys, keep_prob: 0.8})
total_cost += cost_val
if i % 10 == 0:
print('batch:', '%04d' % (i*batch_size), 'cost =', '{:.8f}'.format(cost_val))
print('Epoch:', '%04d' % (epoch+1), 'Avg. cost =', '{:.3f}'.format(total_cost/total_batch))
print('learning finished!!')
iterator_test = dataset_test.make_initializable_iterator()
sess.run(iterator_test.initializer) # Shuffle이 실행됨
image_test, label_test = sess.run(iterator_test.get_next())
batch_xs_test = image_test.reshape(batch_size,784)
batch_ys_test = tf.one_hot(label_test, depth=num_classes).eval(session=sess)
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y,1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('accuracy: ', sess.run(accuracy, feed_dict={X: batch_xs_test, Y: batch_ys_test, keep_prob: 1}))
sess.close()
1. tensorflow와 필요한 라이브러리 import
import tensorflow as tf
import numpy as np
from glob import glob
from PIL import Image
from util import get_label_from_path
from util import data_slice_and_batch
- tensorflow와 numpy를 tf와 np라는 이름으로 import한다.
- 데이터의 path(경로)를 불러오기 위한 glob모듈을, path를 사용해 실제 이미지를 불러오기 위해 PIL에서 Image를 import한다.
- 사용자가 만든 util.py에서 get_label_from_path(경로에서 label를 추려내는 함수)와 data_slice_and_batch(데이터를 batch_size의 크기로 묶어내는 함수)를 import한다.
2. 하이퍼 파라미터 설정
# 1.Hyper Parameter
num_epoch = 2
batch_size = 500
height = 28
width = 28
channels = 1
num_classes = 10
shuffle_buffer_size = 100000
shuffle_buffer_size_test = 20000
- epoch과 batch_size는 각각 2와 500으로 설정하였다.
- mnist dataset의 이미지 크기에 맞춰 height와 width는 각각 28로 설정하였다.
- 흑백이미지이므로 channels는 1로 설정하였다.
- training 및 test dataset 각각 모두 shuffle될 수 있도록 shuffle_buffer_size와 shuffle_buffer_size_test는 각각의 dataset의 크기보다 큰 100,000 and 20,000으로 설정하였다. (# of training dataset: 60,000, # of test dataset: 10,000)
3. traning and test dataset import
# 2-1. Import training dataset
DATA_PATH_LIST = glob('./mnist_png/training/*/*.png')
LABEL_LIST = get_label_from_path(DATA_PATH_LIST)
dataset = data_slice_and_batch(DATA_PATH_LIST, LABEL_LIST, shuffle_buffer_size, batch_size)
# 2-2. Import test dataset
TEST_DATA_PATH_LIST = glob('./mnist_png/testing/*/*.png')
TEST_LABEL_LIST = get_label_from_path(TEST_DATA_PATH_LIST)
dataset_test = data_slice_and_batch(TEST_DATA_PATH_LIST, TEST_LABEL_LIST, shuffle_buffer_size_test, batch_size)
- DATA_PATH_LIST에 training dataset의 모든 경로를 저장한다.
- LABEL_LIST에는 DATA_PATH_LIST에서 추출한 label들이 저장된다.
- data_slice_and_batch함수에서 처리한 정보는 dataset에 저장된다. 학습을 진행할 때 sess.run(iterator.get_next())을 이용하여 batch_size 크기의 이미지 및 라벨정보를 불러올 수 있다.
- TEST가 붙어있는 변수들은 test dataset을 불러오고 정리한 것이다.
4. 모델 디자인
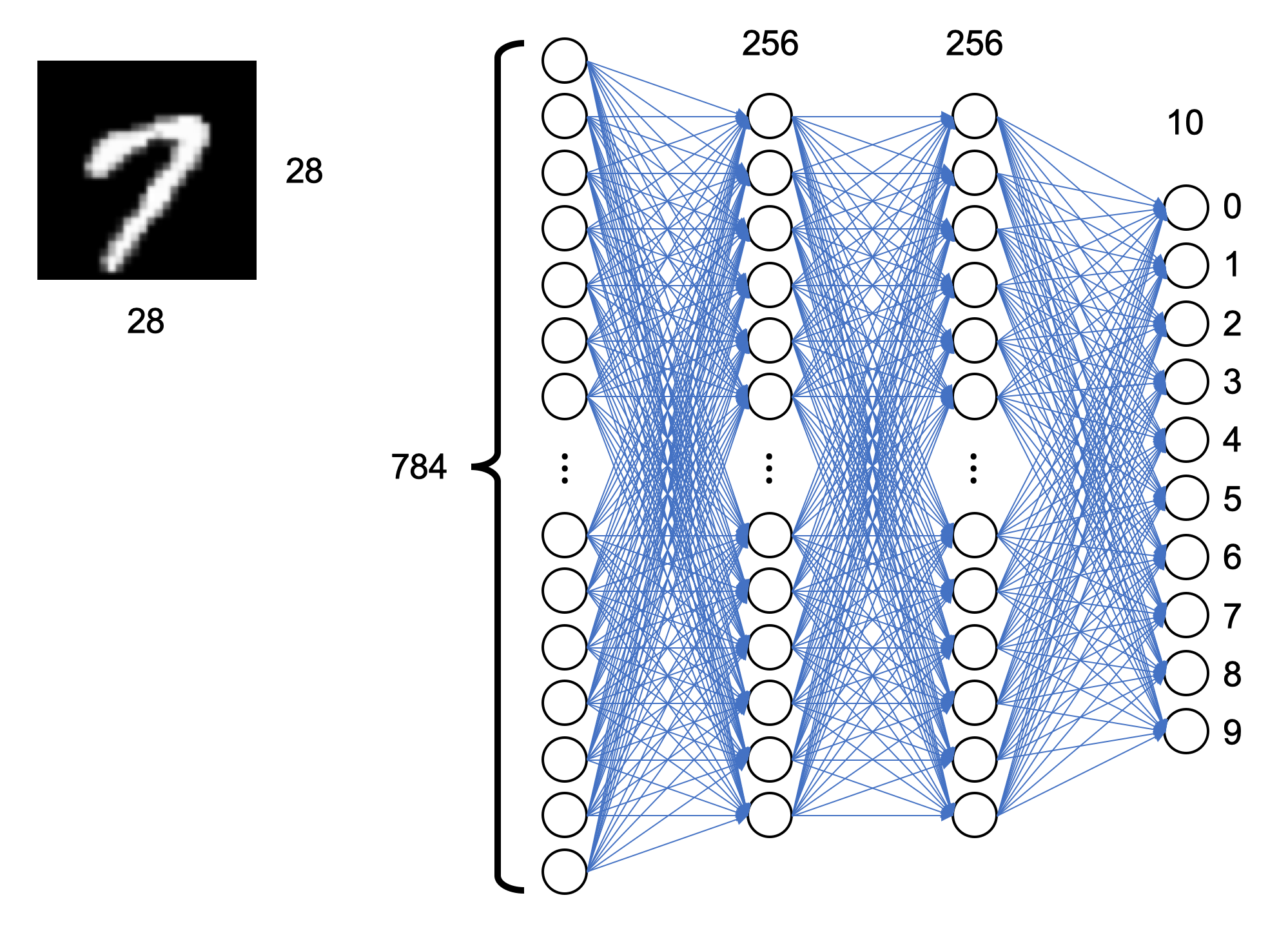
# 3.Model Design
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
W1 = tf.Variable(tf.random_normal([784, 256], stddev=0.01))
L1 = tf.nn.relu(tf.matmul(X, W1))
L1 = tf.nn.dropout(L1, keep_prob)
W2 = tf.Variable(tf.random_normal([256, 256], stddev=0.01))
L2 = tf.nn.relu(tf.matmul(L1, W2))
L2 = tf.nn.dropout(L2, keep_prob)
W3 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
model = tf.matmul(L2, W3)
5. cost function 및 optimizer 선택
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
- cross entroty 함수를 cost function으로 사용한다. model에서 나온 출력값과 y(정답)의 차이를 줄이는 방향으로 학습된다.
- optimizer는 AdamOptimizer를 사용한다. learning rate는 0.001로 설정하였다.
6. 초기화
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
- 변수들을 초기화 한다.
7. 학습
total_batch = int(len(DATA_PATH_LIST)/batch_size)
for epoch in range(num_epoch):
total_cost = 0
iterator = dataset.make_initializable_iterator()
sess.run(iterator.initializer) # Shuffle이 실행됨
for i in range(total_batch):
# batch_xs, batch_ys = mnist.train.next_batch(batch_size)
image, label = sess.run(iterator.get_next())
batch_xs = image.reshape(batch_size,784)
batch_ys = tf.one_hot(label, depth=num_classes).eval(session=sess)
# print(batch_ys)
a, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys, keep_prob: 0.8})
total_cost += cost_val
if i % 10 == 0:
print('batch:', '%04d' % (i*batch_size), 'cost =', '{:.8f}'.format(cost_val))
print('Epoch:', '%04d' % (epoch+1), 'Avg. cost =', '{:.3f}'.format(total_cost/total_batch))
print('learning finished!!')
- total_batch = 60,000 / batch_size(500) = 120
- num_epoch=2이기 때문에 60,000개의 데이터가 2번 학습된다.
- 매 epoch마다 total_cost 및 average_cost를 계산하기 위해 total_cost를 0으로 설정한다.
- iterator를 정의하고 sess.run(iterator.initializer)를 실행하면 데이터가 shuffle된다. 위의 코드에서는 매 epoch마다 shuffle을 진행한다.
- sess.run(iterator.get_next())의 출력값으로 image와 label에 batch_size(500개)만큼의 이미지와 이에 상응하는 라벨값들이 저장된다.
- [batch_size, 28, 28]의 shape을 가지고 있는 image를 입력의 모양이 [batch_size, 784]인 model에 넣기 위해 shape을 바꿔서 batch_xs에 넣어준다.
- 0,1,2,...,8,9로 저장되어 있는 라벨값을 one_hot_vector(정답의 index는 1, 나머지 index는 모두 0)를 만들기 위해 tf.ont_hot 함수를 이용하여 ont hot encoding을 한다.
- batch_xs와 batch_ys를 feed_dick을 이용하여 model에 넣고 sess.run으로 optimizer와 cost를 실행한다. dropout의 비율은 0.8로 설정하였고, cost_val를 출력하여 cost가 얼마나 줄어드는지 10번의 batch만큼(i%10==0) 학습이 진행될 때마다 확인한다.
- epoch이 끝날때마다 매 opoch의 평균 cost를 계산하여 출력한다.
8. Testset을 이용하여 Accuracy 확인
iterator_test = dataset_test.make_initializable_iterator()
sess.run(iterator_test.initializer) # Shuffle이 실행됨
image_test, label_test = sess.run(iterator_test.get_next())
batch_xs_test = image_test.reshape(batch_size,784)
batch_ys_test = tf.one_hot(label_test, depth=num_classes).eval(session=sess)
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y,1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('accuracy: ', sess.run(accuracy, feed_dict={X: batch_xs_test, Y: batch_ys_test, keep_prob: 1}))
sess.close()
- training set에서 진행했던 것처럼 testset을 불러와서 batch_xs_test와 batch_ys_test에 batch_size 크기만큼 저장한다. 모든 testset를 이용해서 Accuracy를 계산하려면 batch_size의 크기를 testset의 크기(10,000)으로 조절한다.
- model에서 inference한 값과 이에 상응하는 y값이 일치하면 True, 일치하지 않으면 False를 출력하는데 이를 float32값으로 바꿔 accuracy를 계산한다.
- accuracy를 계산할때는 학습할때와 달리 keep_prob를 1로 설정하여 dropout없이 모든 weight를 사용한다.
- accuracy까지 모두 계산하면 Session을 종료한다.
'딥러닝 > Your own dataset' 카테고리의 다른 글
| CNN code - your own mnist dataset (0) | 2020.04.27 |
|---|---|
| CNN code - your own mnist dataset - Tensorflow API (0) | 2020.03.21 |
| mnist your own dataset - tensorflow.data.Dataset 3 (0) | 2019.08.13 |
| mnist your own dataset - tensorflow.data.Dataset 2 (0) | 2019.08.09 |
| mnist your own dataset - tensorflow.data.Dataset 1 (2) | 2019.07.26 |