오늘 제가 리뷰할 논문은 "Toward Automatic Annotation for Semantic Segmentation in Drone Videos"입니다. 이 논문은 2019년 10월에 archive에 게재되었고, ICRA 2020에도 제출되었습니다. Semantic Segmentation을 supervised learning을 이용하여 하기 위해서는 많은 annotation image들이 필요합니다. 이 논문은 드론으로 촬영한 Video(초당 50장)를 기반으로, 소수의 이미지들을 manually annotation 하고(초당 1장), 이를 기반으로 많은 수의 이미지(나머지 49장)를 automatic annotation 할 수 있는 "SegProp" 방법에 대해 소개하는 논문입니다.

Introduction
드론으로 촬영한 이미지를 Semantic Segmentation 이미지로 annotation 하는데에는 다음과 같은 어려움들이 있습니다.
- Very large object scale/pose variations
- More degrees of freedom (unconstrained movement)
- Hard to annotate
- Less work compared to ground-level videos
드론에서 촬영한 이미지들은 (1) Annotation 하려는 object들의 크기와 자세의 변화가 크고, (2) 드론 이미지는 큰 Degree of freedom을 가지고 있습니다(자동차에서 촬영한 영상은 사람의 옆면, 일정한 모양의 도로 등이 촬영됨, 위성에서 촬영한 영상은 항상 위에서 바라보는 이미지, 드론에서 촬영한 영상은 다양한 각도에서 object를 촬영하여 하나의 object도 다양한 모양이 존재). (3) 이러한 이유 때문에 Annotation 하기 어렵고, (4) 드론 영상의 경우, 자동차(ground-level) 또는 위성(Remote Sensing) 이미지에 비해 Annotation 된 이미지의 수가 더 적습니다.
본 논문에서는 automatic annotation 방법에 대해 기술하고 있습니다. 비록 드론에서 촬영한 이미지를 기반으로 automatic annotation 방법을 기술하고 있지만, automatic annotation 방법은 어떤 이미지를 기반하든 굉장히 가치있는 능력입니다. 따라서 이 논문에서 제시한 SegProp는 어떠한 종류의 이미지이든, sequentially 촬영된 이미지를 semantic segmentation 이미지로 annotation 하는데 굉장히 유용할 것으로 생각됩니다.
Overview of Proposed Method
제안된 방법은 아래와 같이 3가지의 procedure에 따라 진행됩니다.

A. Sampling and Labeling
드론을 이용해서 50 FPS(frame per seconds)의 rate로 video를 촬영합니다. 그중에서 1초에 1개의 이미지를 선택하고, manually annotation 합니다. 촬영한 video의 이미지 수는 50,835개, manually annotation 한 이미지는 2%에 해당하는 1,047 개입니다.
B. Automatic Annotation
드론에서 촬영한 이미지는 연속된 이미지라는 특징을 가지고 있습니다. 연속된 이미지들 중에서, 이 논문에서는 1초당 1장씩 sparse 하게 이미지를 manually annotation 했습니다. 본 논문에서 제안하는 Automatic annotation 알고리즘의 핵심은 manually annotation 된 이미지들의 사이에 있는 49개의 이미지들을 자동으로 annotation 하는 것입니다. (그러려면 1초마다 video의 이미지들은 선형적으로 움직여야 할 것이고, 이 알고리즘을 사용하기 위해서, 우리는 선형적으로 object들이 변하도록 촬영해야 할 것으로 생각됩니다.) 만약 manually annotation 한 이미지들이 이전 frame에서 다음 frame까지 얼마나 변했는지 알 수 있다면, manually annotation한 이미지를 기반으로 그 변화량만큼 새로운 Semactic Segmentation 이미지를 automatic annotation 할 수 있습니다.
C. Training and Validation
Automatic annotation method의 성능을 확인하기 위해, manually annotation(1,047장) 이미지를 입력으로 학습한 결과와 manually + automatic annotation(50,835장)를 입력으로 학습한 결과를 비교하였습니다.
Automatic Annotation with SegProp
SegPro 알고리즘은 기본적으로 voting 기법을 기반으로 작동합니다. 아래의 그림에서 빨간색 사각형이 어떤 class인지 결정하기 위해서 각각의 method들은 자신만의 기준으로 빨간색으로 표시된 pixel이 어떤 class인지 예측합니다. 그리고 다수결을 통해서 가장 많은 빈도로 예측된 class를 정답으로 결정합니다. 이 논문에서는 optical flow로 4가지, homography로 2가지 기준을 정해서, 총 6가지 방법으로 voting을 수행했습니다.

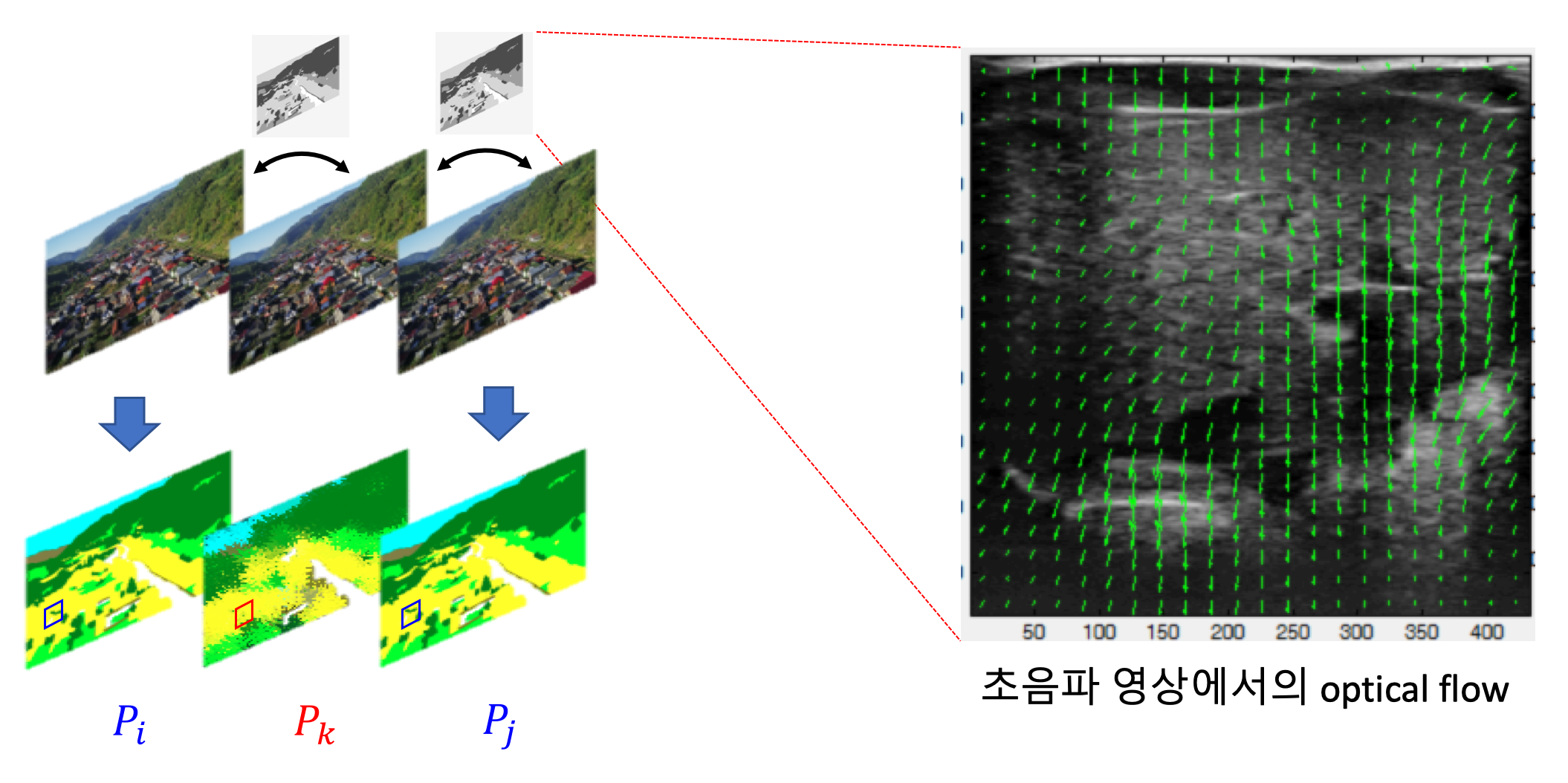
A. Optical Flow
파란색으로 표시한 부분은 manual로 annotation한 이미지이고, 빨간색으로 표시한 부분은 automatically annotation 되어야 할 이미지를 나타냅니다. Optical flow는 오른쪽에서 볼 수 있는 초음파 사진처럼 이전 frame에서 다음 frame까지 pixel이 얼마나 움직였는지 vector로 나타내는 것을 말합니다. 즉, optical image는 두 이미지의 변화량을 나타낸다고 생각할 수 있습니다. SegProp는 Pi에서 Pk로, Pk에서 Pi로의 optical flow를 계산해서 이미지 사이의 변화량을 알아냅니다. 그리고 manually annotation 한 이미지를 위에서 계산한 변화량만큼 각 pixel을 이동시키면 우리는 automatically 각 pixel의 class를 추정할 수 있습니다.
B. Homography estimation
Optical flow는 intensity가 일정하다고 가정을 하는데, intensity는 순간적으로 계속 변하기 때문에 optical flow는 noise를 항상 동반합니다. 그래서 이 논문에서는 좀 더 robust 하게 automatic annotation을 하기 위해서 manual로 annotation 한 두 이미지 사이의 homography estimation을 사용했습니다. (The homography based voting is particularly useful in edge preservation where the CNN-based optical flow generally lacks precision.)
오른쪽의 그림은 homography estimation에 대한 설명을 나타냅니다. 4개의 keypoint가 있으면 마름모 모양에서 직사각형으로 변환시킬 수 있는 h로 이루어진 homography matrix를 estimation 할 수 있습니다. Homography는 두 이미지에서 서로 매칭 되는 keypoint들을 잘 찾아야 정확한 estimation이 이루어집니다. 먼저 두 개의 이미지에서 feature들을 추출하고 서로 매칭을 시킵니다. 그러면 노란색처럼 잘 매칭 된 것도 있고 빨간색처럼 잘못 매칭된 keypoint들도 있습니다. 그 후, 매칭된 feature들 사이의 translation vector의 평균을 구해서 평균가 너무 동떨어진 feature들은 제거합니다. 이러한 방법을 iterative 하게 반복하면 결국 잘 매칭이 되는 keypoint들만 남게 되고, 이 keypoint들을 이용해서 homography matrix을 estimation 합니다.
Homography estimation을 이용하기 위해서 먼저 왼쪽의 그림처럼 ground truth에 있는 label을 연결된 class들끼리 grouping을 합니다. Grouping 한 지역 내에서 feature들을 추출하고 두 frame 사이의 homography를 계산합니다. 계산된 homography를 기반으로 manual annotation 한 semantic segmentation 이미지를 translation 해서 automatic annotation을 합니다.

Experimental Analysis
생성한 dataset을 학습에 사용하기 위해서 아래와 같이 데이터를 나누었습니다.

A. Semantic Segmentation
Semantic Segmentation 알고리즘은 UNet을 기반으로 만들어졌습니다. 먼저 4K 이미지를 입력으로 넣고 2번의 convolution, 1번의 maxpooling 과정을 3번 반복합니다. 만들어진 feature map을 Dilation 1,2,4,8,16을 하여 concatenate 하고 transposed convolution을 이용해서 upscalling 합니다. Upscalling 한 feature map은 Downsampling Blocks에서 상응하는 layer와 concatenate 합니다. 이 과정을 3번 반복하여 최종적으로 Semantic Segmentation 이미지를 inference 합니다.

B. Comparison with other methods for label propagation
아래의 그림은 SDCNet이라는 딥러닝 알고리즘입니다. Sequential 한 이미지에서 FlowNet2를 통해 optical flow 이미지를 추출합니다. 그리고 Sequential한 이미지와 optical flow 이미지를 기반으로 크기 변화량 등(K(x, y))과 이동량(u(x, y)) 등을 나타내는 변수를 예측하여 I(t) 이미지에서 I(t+1) 이미지를 예측하는 알고리즘입니다. SDCNet의 input으로 I(t) 대신에 manual annotation 된 semantic segmentation 이미지를 넣어주면 automatic annotation이 가능한 것 같습니다.

성능 지표는 F-measure를 사용했습니다. 아래의 표를 통해서 SDCNet과 SegProp를 비교했을 때, SegProp의 성능이 더 좋은 것을 확인할 수 있습니다. SegProp는 voting algorithm을 기반으로 작동하고 있습니다. 그래서 SDCNet에서 2 vote를 더하여 8개의 기준으로 voting을 진행해서 성능이 더 좋아지는 것도 확인되었습니다. 이러한 결과를 통해 SegProp는 성능이 좋은 automatic annotation 알고리즘이 나오면 또 다른 voting 방법으로 사용하여 성능을 더 높일 수 있는 장점이 있는 것을 확인할 수 있습니다.

C. Experimental Results
아래의 그림은 manual annotation 이미지를 SafeUAV-NET-Large의 input으로 사용해서 학습한 모델과 manual+automatic annotation 이미지를 input으로 사용해서 학습한 모델의 inference를 결과를 각각 보여줍니다. 첫 번째 row에서는 사람들을 좀 더 잘 segmentation 하도록 모델이 개선되었습니다. 두 번째 row에서는 왼쪽 상단의 forest를 잘못 segmentation 하고 있지만 교회는 좀 더 잘 segmentation하고 있습니다. 세 번째 row에서도 사람 또는 fence 등을 좀 더 잘 segmentation 하는 것을 확인할 수 있습니다.

Conclusion
본 논문은 automatic segmentation 방법에 대해 설명하였습니다. Automatical annotation을 하기 위해서 optical flow와 homography를 이용했고, 이러한 방법으로 4K video dataset에 대해서 50,835 images / 12 classes의 Ruralscapes dataset을 만들 수 있었습니다. 성능적인 면에서는 직접 제작한 Ruralscapes에 대해서 SOTA를 기록했습니다. 또한 SegProp는 voting 알고리즘을 기반으로 작동하기 때문에 다른 유사한 알고리즘과 쉽게 integration 될 수 있는 장점을 가지고 있기 때문에, 다른 유사한 알고리즘이 제안되면 더 발전될 가능성이 있는 알고리즘입니다.

Reference
Paper URL and Website
[1] https://arxiv.org/abs/1910.10026
[2] https://sites.google.com/site/aerialimageunderstanding/home
Blog
[3] https://www.cc.gatech.edu/~afb/classes/CS4495-Fall2014/slides/CS4495-Ransac.pdf
[4] https://people.cs.umass.edu/~elm/Teaching/ppt/370/370_10_RANSAC.pptx.pdf
[5] https://paeton.tistory.com/entry/%EC%98%B5%ED%8B%B0%EC%B9%BC-%ED%94%8C%EB%A1%9C%EC%9A%B0-Optical-Flow
[6] https://en.wikipedia.org/wiki/Lucas%E2%80%93Kanade_method

'논문 Review' 카테고리의 다른 글
| Free LSD: Prior-Free Visual Landing Site Detection for Autonomous Planes (0) | 2020.03.02 |
|---|---|
| An automatic zone detection system for safe landing of UAVs (0) | 2020.02.22 |
| ICNet: Real-time Semantic Segmentation on High Resolution Images (0) | 2020.02.14 |
| PSPNet - Pyramid Scene Parsing Network (0) | 2019.06.27 |